[Monitoring] zabbix 3편: zabbix DB 파티셔닝 적용 가이드
Zabbix를 운영하면서 반드시 마주하게 되면 'DB 부하 및 용량 관리' 문제를 해결하기 위한 DB 파티셔닝(Partitioning)에 대해 알아보겠습니다.
Zabbix는 수천, 수만 개의 아이템 데이터를 실시간으로 수집하여 DB에 저장합니다. 시간이 흐를수록 데이터는 기하급수적으로 쌓이고, 이를 삭제하는 과정에서 시스템 성능이 급격히 저하될 수 있습니다. 이를 우아하게 해결하는 방법이 바로 파티셔닝 입니다.
본 가이드는 MariaDB를 기반으로 설명합니다.
DB 파티셔닝이 왜 필요하지?
Zabbix에는 Housekeeper라는 프로세스가 있습니다. 설정된 보관 주기(History storage period)가 지는 데이터를 자동으로 삭제해 주는 고마운 존재 입니다.
- Housekeeper의 한계 : 데이터 삭제시
DELETE쿼리를 사용합니다. 데이터가 많을수록 인덱스 재구성 및 트랜젝션 로그 발생으로 인해 DB에 큰 부하를 줍니다. - 파티셔닝의 장점 : 데이터를 날짜별 "방"으로 나누어 저장합니다. 삭제 기한이 지나면
DELETE대신DROP PARTITION명령을 사용합니다. 이는 테이블 전체를 건드리지 않고 파일 자체를 삭제하는 방식이라 DB부하가 거의 없으며 속도가 압도적으로 빠릅니다.
Zabbix 주요 테이블을 이해해 봅시다.
파티셔닝을 적용하기 전, 어떤 테이블이 데이터를 많이 사용하는지 알아야 합니다.
|
테이블 분류 |
주요 테이블명 |
저장 데이터 유형 |
관리 방식 |
|
History (상세 데이터) |
history, history_uint, history_str, history_log, history_text |
CPU 사용률, 로그 메시지 등 수집된 원시 값 (Raw Data) |
일별(Daily) 파티셔닝 권장 |
|
Trends (통계 데이터) |
trends, trends_uint |
시간당 최소/최대/평균값 집계 데이터 |
월별(Monthly) 파티셔닝 권장 |
단계별 파티셔닝 적용 방법
주의! 파티셔닝 작업은 테이블 구조를 변경하는 대규모 작업입니다. 반드시 Zabbix Server를 중단하고 진행하세요.
systemctl stop zabbix-server기존 데이터 날짜 확인
먼저 각 테이블에 저장된 가장 오래된 데이터의 날짜를 확인하여 파티션 시작점을 잡습니다.
SELECT FROM_UNIXTIME(MIN(clock)) FROM `history`;일별 파티셔닝 적용(History 테이블 예시)
history 테이블을 현재 날짜를 기준으로 파티셔닝합니다. (아래 쿼리는 예시 날짜이므로 실제 환경에 맞춰 조정하세요.)
ALTER TABLE `history` PARTITION BY RANGE (clock)
(
PARTITION p2025_03_11 VALUES LESS THAN (UNIX_TIMESTAMP('2025-03-12 00:00:00')) ENGINE = InnoDB,
PARTITION p2025_03_12 VALUES LESS THAN (UNIX_TIMESTAMP('2025-03-13 00:00:00')) ENGINE = InnoDB,
-- ... 중략 ...
PARTITION p2025_04_11 VALUES LESS THAN (UNIX_TIMESTAMP('2025-04-12 00:00:00')) ENGINE = InnoDB
);월별 파티셔닝 적용(Trends 테이블 예시)
통계 데이터는 데이터 양이 상대적으로 적으므로 월 단위로 관리 합니다.
ALTER TABLE `trends` PARTITION BY RANGE (clock)
(
PARTITION p2025_02 VALUES LESS THAN (UNIX_TIMESTAMP('2025-03-01 00:00:00')) ENGINE = InnoDB,
PARTITION p2025_03 VALUES LESS THAN (UNIX_TIMESTAMP('2025-04-01 00:00:00')) ENGINE = InnoDB
);파티셔닝 자동화 관리(Bash Script)
매일 수동으로 파티션을 생성할 수는 없겠죠? 아래 스크립트를 활용해 신규 파티션 생성(Add)과 오래된 파티션 삭제(Drop)를 자동화할 수 있습니다.
#!/bin/bash
# set -ex
# 파티션 생성 :
# - 일별 : 매일 오후 11시에 다음날 파티션 생성 (00 23 * * * root zabbix_db_partitioning.sh add daily)
# - 월별 : 매월 말일 오후 11시에 다음달 파티션 생성 (00 23 * * * root [ $(date +\%d) = 01 ] && zabbix_db_partitioning.sh add monthly)
# 파티션 삭제 :
# - 일별 : 매일 오전 00시 이후 실행 되고 현재 일 기준 365일 이전 파티션 삭제 (00 00 * * * root zabbix_db_partitioning.sh drop daily)
# - 월별 : 매월 1일 오전 00시 이후 실행 되고 현재 월 기준 12개월 이전 파티션 삭제(00 00 1 * * root [ $(date +\%d) = 01 ] && zabbix_db_partitioning.sh drop monthly)
DB="zabbix"
MYSQL="mysql"
if [ "$2" == "daily" ]; then
TABLES="history history_log history_str history_uint history_text"
KEEP=365
NEXT=$(date -d "+1 day" +"%Y-%m-%d")
# NEXT_TIMESTAMP=$(date -d "$NEXT" +%s)
NEXT_PARTITION="p$(date -d "$NEXT" +"%Y_%m_%d")"
LESS_THEN=$(date -d "+2 day" +"%Y-%m-%d")
DROP_DATE=$(date -d "-$KEEP day" +"%Y-%m-%d")
DROP_PARTITION="p$(date -d "$DROP_DATE" +"%Y_%m_%d")"
elif [ "$2" == "monthly" ]; then
TABLES="trends trends_uint"
KEEP=12
NEXT=$(date -d "+1 month" +"%Y-%m-01")
# NEXT_TIMESTAMP=$(date -d "$NEXT" +%s)
NEXT_PARTITION="p$(date -d "$NEXT" +"%Y_%m")"
LESS_THEN=$(date -d "+2 month" +"%Y-%m-01")
DROP_DATE=$(date -d "-$(($KEEP - 1)) month" +"%Y-%m-01")
DROP_PARTITION="p$(date -d "$DROP_DATE" +"%Y_%m")"
else
echo "Usage: $0 {daily|monthly}"
exit 1
fi
for table in $TABLES
do
if [ "$1" == "add" ]; then
# 파티션 생성 SQL
ADD_PARTITION_SQL="ALTER TABLE $DB.$table ADD PARTITION (PARTITION $NEXT_PARTITION VALUES LESS THAN (UNIX_TIMESTAMP('${LESS_THEN}')));"
# echo $ADD_PARTITION_SQL
echo "Adding partition: $NEXT_PARTITION"
$MYSQL $DB -e "$ADD_PARTITION_SQL"
VALIDATION_QUERY="SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, PARTITION_ORDINAL_POSITION, TABLE_ROWS FROM information_schema.PARTITIONS WHERE TABLE_NAME = '${table}' AND PARTITION_NAME = '${NEXT_PARTITION}';"
$MYSQL $DB -e "$VALIDATION_QUERY" > /root/logs/${table}_$(date +%Y-%m-%d)_validation.log
elif [ "$1" == "drop" ]; then
# 파티션 삭제 SQL
DROP_PARTITION_SQL="ALTER TABLE $DB.$table DROP PARTITION $DROP_PARTITION;"
# echo $DROP_PARTITION_SQL
echo "Dropping old partition: $DROP_PARTITION"
$MYSQL $DB -e "$DROP_PARTITION_SQL"
else
echo "Usage: $0 {add|drop} {daily|monthly}"
exit 1
fi
donezabbix_db_partitioning.sh
Crontab에 등록하여 주기적으로 실행하세요.
- 매일 23:00 : 다음날 파티션 미리 생성
- 매일 00:01 : 보관 주기가 지난 과거 파티션 삭제
00 23 * * * /path/zabbix_db_partitioning.sh add daily
01 00 * * * /path/zabbix_db_partitioning.sh drop daily
00 23 * * * [ $(date +\%d) = 01 ] && /path/zabbix_db_partitioning.sh add monthly
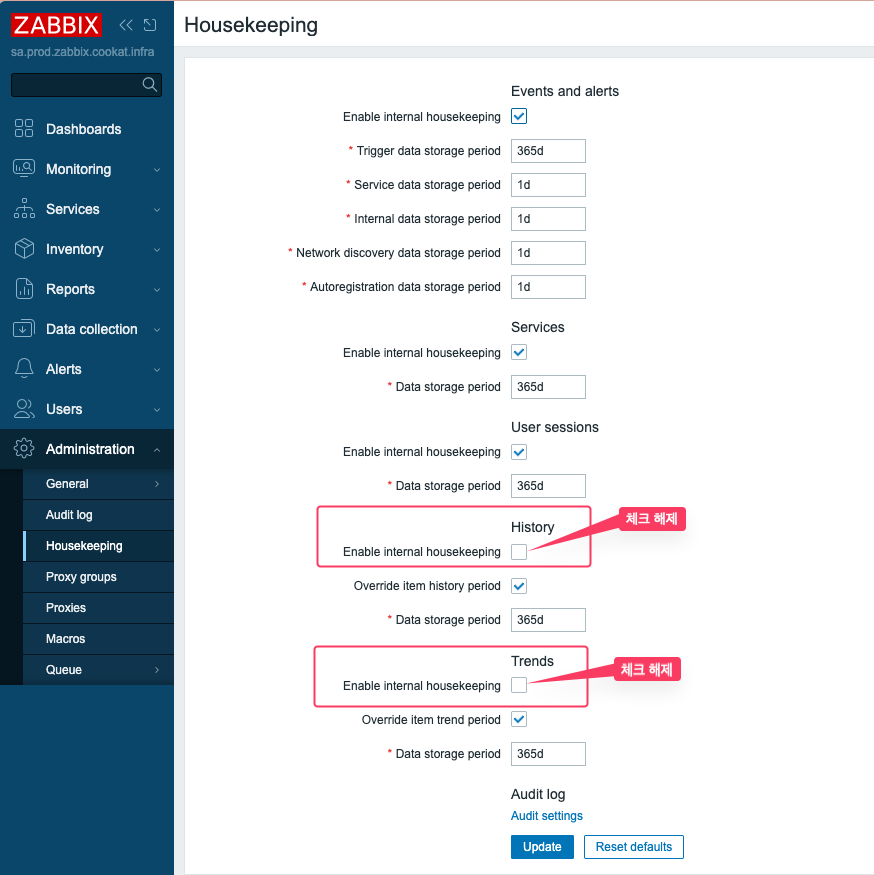
01 00 * * * [ $(date +\%d) = 01 ] && /path/zabbix_db_partitioning.sh drop monthly마무리 설정 : Housekeeper 비활성화
파티셔닝을 완료 했다면, 더 이상 Zabbix 내부의 Housekeeper가 history와 trends 데이터를 건드를 필요가 없습니다.
- Zabbix 웹 GUI 접속 :
Administration>Housekeeping History와Trends의Enable internal housekeeping을 체크 해제합니다.- 이제 DB관리는 파티셔닝 스크립트가 전담하게 됩니다.
요약하며
DB 파티셔닝은 초기 설정이 다소 번거로울 수 있지만, 대규모 모니터링 환경에서 DB안정성과 성능을 보장하는 유일한 방법입니다. Zabbix 서버가 느려지거나 DB용량 부족으로 고민중이라면 지금 바로 적용해 보세요!
Tip : 작업 전 DB백업은 필수 입니다. 예상치 못한 오류에 대비하세요.